最近は Python をちょこまかといじることが増えてきたように感じています。というところで、クラスタリングのことを調べていたのですが、なんとなく k-means しておけばいいっしょ、くらいだったのですが、もっと奥深い色々が出てきて、クラスタリングわからないマンになりつつあります。そんなわけで、階層型クラスタリングを調べて、やってみたのでまとめておきます。
クラスタリングとは
クラスタリングとはデータを良い具合にまとめるという、教師なし学習の典型例です。何かしらの特徴量に沿って、データの流れや雰囲気をアルゴリズム的に見抜き、その様子でデータをまとめることができます。
クラスタリングとしてもっとも一般的なものは k-means でしょうか。k-means は非階層型クラスタリングと呼ばれています。具体的には以下のようなアルゴリズムでクラスタリングを行います。
- 事前に設定されるクラスタ数 K を元に、ランダム(※)にクラスタの中心を決定する
- 各要素から一番近いクラスタの位置を探し、それを各要素のクラスタとして設定する
- 各クラスタの重心を計算し、その重心位置をクラスタの中心として設定する
- 各要素から一番近いクラスタの位置を探し、それを各要素のクラスタとして設定する
- 各クラスタの重心を計算し、その重心位置をクラスタの中心として設定する
- ...これを重心の移動がしきい値を下回るまで、あるいは指定の回数を超えるまで実施する
- 最終的に、各要素から一番近いクラスタの位置が、その要素のクラスタとして決定される
(イメージ図@雑)
※ランダムにするか、程よい位置にするか(k-means++)などの初期位置決定の方法があります
後述する階層型との比較でも挙げますが、初期位置によってある程度クラスタの別れ方が分岐することも往々にして発生します。また、クラスタリング結果が毎回異なる可能性もあり、厳密な分類がほしい、なんとなく纏めるでは嫌、といった場合の要望をかなえることはできません。かといって階層型クラスタリングがこの要望を常に叶えられるわけでもないのですが…
今回取り上げる階層型との比較として後述しますが k-means では、事前にクラスタ数を設定する必要があるため、それが難しいような状況では大きな力を発揮することが難しいです。
ちなみにアルゴリズムとして x-means という、クラスタ数を自動で設定できるものもあります。K=2 として再帰的に k-means を実施し BIC と呼ばれるベイズ情報量規準が、設定したしきい値を下回るまで実行していくようなものになっています。詳しいことはぼくもあまりわからないので、その話が上がっている論文を見ると幸せになれると思います。
http://www.rd.dnc.ac.jp/~tunenori/xmeans.html
機械学習について触れていると、似たような「クラス分類」といったワードを見かけたこともあるかと思います。こちらはクラスタリングとは異なり、教師あり学習で「あるデータがどのクラスに属しているかを当てる」という全く別の問題になります。リンゴは果物、キャベツは野菜、というような、明確に正解があるようなデータを分類していくときには、クラス分類になります。
階層型クラスタリングとは
階層型クラスタリングは以下のようなアルゴリズムで処理されます。
- すべての要素に固有のクラスタを設定する
- クラスタを2つ取り上げていき、最も距離が近いもの(※)をくっつけて、新しいクラスタを作成する
- これを再帰的に実行し、最終的にクラスタが1つになるまで実施する
※「距離」の定義は設計次第です。ユークリッド距離、コサイン距離、など様々な計算方法があります。
※くっつけて出来上がったクラスタ間の距離計算は設計次第です。
- クラスタが含む要素をそれぞれ比較し、最も近いものを距離とする(最近隣法)
- クラスタが含む要素をそれぞれ比較し、最も遠いものを距離とする(最遠隣法)
- クラスタが含む要素をそれぞれ比較し、平均的な距離とする(平均法)
- クラスタが含む要素をそれぞれ比較し、それぞれの距離について分散を利用して程よい値を取る(ウォード法、よく使われているらしい)
(イメージ図@雑)
そうして出来上がったクラスタリング結果ですが、このままでは木構造のようになっており、データとして扱うにはどれがどういうクラスタに属しているのかを明確に決定しにくいです。実際にあるタスクで利用したときには、最大距離の7割を基準にして、クラスタを分割していました。状況によってはパラメータの調整する必要がありそうな予感がしています。
計算量と実際にかかる時間を考慮すると、既に説明した k-means や、この階層型クラスタリングが高速に処理でき、「それっぽい結果」が得られるので、解決したい問題にも寄ってくるとは思いますが、クラスタリングにおける選択肢として現実的なのかなあと思います。
階層型・非階層型(k-means)のそれぞれの使いどころ
階層型が活用できそうなところは以下のようなところではないでしょうか?
- データセットのうち、それぞれの距離に何かしらの特徴がありそう
- どれくらいのクラスタに分けたらいいかわからない
階層型の場合。クラスタ間の距離で並べ替えることも容易にできるはずなので、しきい値の設定が小さいせいでクラスタを分けすぎてしまっても、ある程度までは前後関係もそれっぽく追いついてきます。なので、出来上がった後に、人力でカバーすることも可能なのではないかなあと思います(それってどうなの感はありますが…)あるいはクラスタ数がいくつになるか想定できないような場合にも、全てのデータを一度まとめあげるので、自動で出てきた結果の様子を見つつ、手動でクラスタ分けしていくことができると思います。
一方で非階層型…もとい k-means の活用できそうなところは以下のようなところではないでしょうか?
- データセットの雰囲気がわからないけど、いったん分割してみたい
- 明確に K 個の分類をしたい
k-means では最初に K を決定しないといけないので、どうあがいても K 個のクラスタができあがります。この分ける数が重要になるような、クラス分類に近いようなものの場合であれば k-menas は非常に有効なのではないでしょうか。ただし、それぞれのクラスタ間で相関がないことや、中途半端な位置のデータはどちらとも言えないような結果になることは注意がいるかもしれません。
また、どんなデータを入れても、なんとなくまとめてくれるので、人力で確認したときも、「ああーこういう見方もあるのね、なるほど」という謎の納得感が得られやすいとも思います。
階層型クラスタリングを Python でやってみる
それでは Python で 階層型クラスタリングをやっていきます。ここでは sciki-learn に入っているアイリスデータセットを対象に pandas で読み込んで scipy.cluster.hierarchy を使っていきます。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
from sklearn.datasets import load_iris
# iris データセットの読み込み
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_labels = list(map(lambda t: iris.target_names[t], iris.target))
# 階層型クラスタリングの実施
# ウォード法 x ユークリッド距離
linkage_result = linkage(iris_df, method='ward', metric='euclidean')
# クラスタ分けするしきい値を決める
threshold = 0.7 * np.max(linkage_result[:, 2])
# 階層型クラスタリングの可視化
plt.figure(num=None, figsize=(16, 9), dpi=200, facecolor='w', edgecolor='k')
dendrogram(linkage_result, labels=iris_labels, color_threshold=threshold)
plt.show()
# クラスタリング結果の値を取得
clustered = fcluster(linkage_result, threshold, criterion='distance')
# クラスタリング結果を比較
print(clustered)
print(iris.target)
出力結果
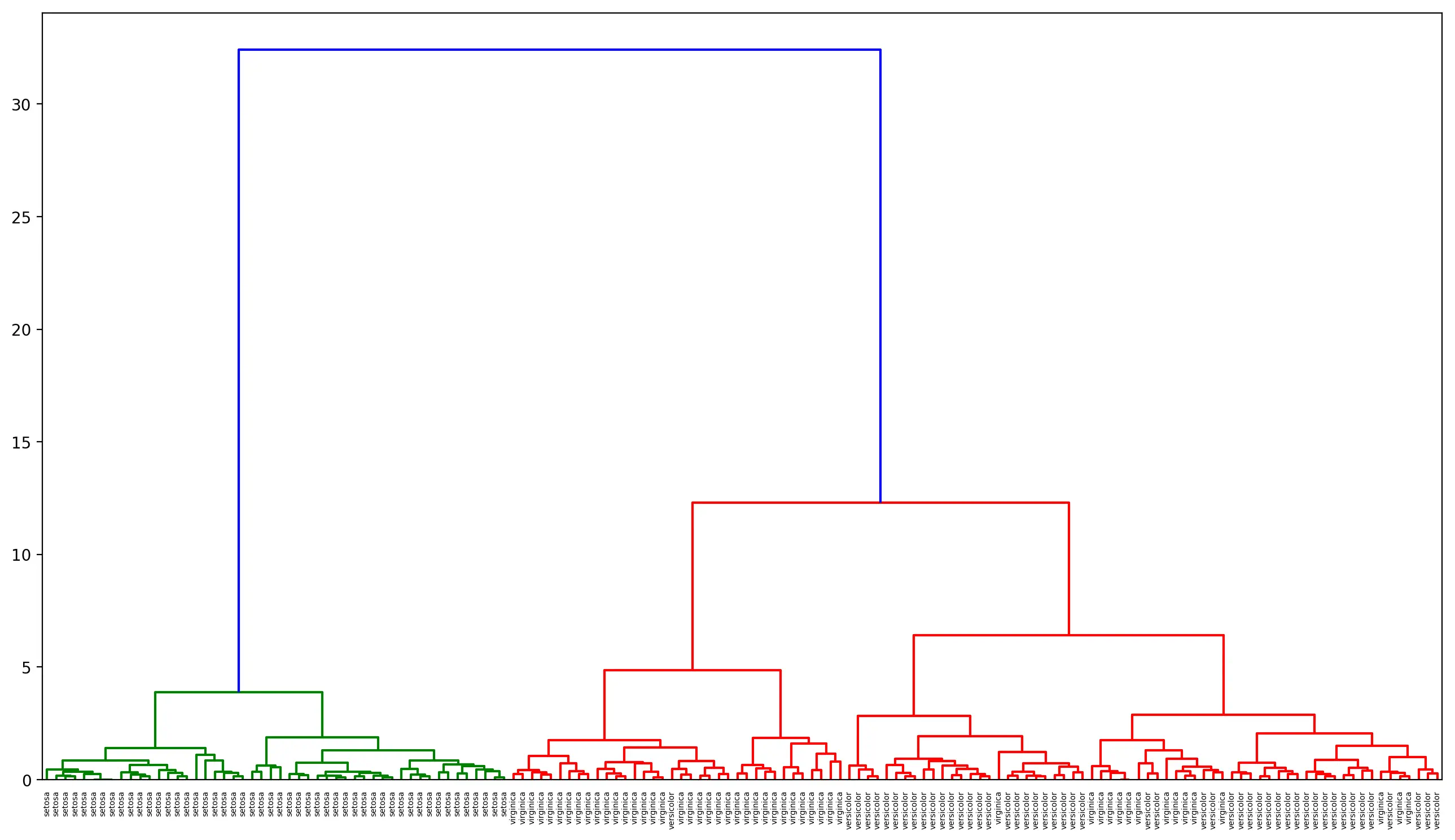
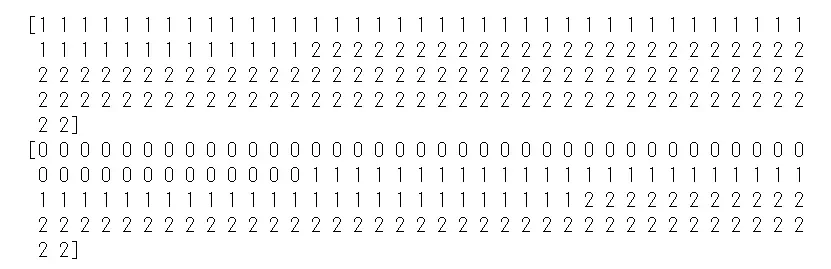
様子も見ずデータを絞ったりせず全てぶっこんで、というのはちょっと微妙なところですが setosa だけキレイに分かれましたね。setosa と、それ以外とで距離に開きがあるので、setosa だけ非常に特徴的ってことがわかります。それで versicolor と virginica はぼちぼち似ている、なんてところですね。
というわけで、階層型クラスタリングの話でした。
余談にはなりますが、そんなこんなで出来たやつをいい感じにクラスタ分けしたよ~^^って渡したら、分岐したやつを画像じゃなくて csv とかで欲しいって言われたのでそれはまた。